
分析师/智涵 校对/Tina 策划/Eason
今天凌晨,科技媒体圈被一条消息刷屏:DeepSeek拟募资最高500亿元人民币,投后估值剑指3500亿元(约515亿美元),梁文锋个人出资或最高达200亿元人民币。如果落地,这将刷新中国AI公司单轮融资的历史纪录。
但这个故事最戏剧性的部分,不是数字本身,而是说这句话的主角——一家成立近三年、从未拿过外部VC一分钱的公司,一家曾被创始人梁文锋定性为“做研究、做探索,不做垂类和应用”的AI实验室。
四轮传闻,一个月内估值翻了三倍以上。从4月中旬首次传出“不低于100亿美元”融资目标,到4月22日的200亿美元,再到5月6日的450亿美元,最后到5月8日传出的投后约515亿美元——DeepSeek一次都没有辟谣。而就在2025年,它还曾两次公开澄清“融资为谣言”。
态度的转变,比任何知情者的爆料都更真实。当“技术极客”躬身资本局,问题就不再是“融不融”,而是“为什么是现在”以及“这意味着什么”。
01
融资不是为了“搞钱”,
而是为了“留人”和“买时间”
首先需要纠正一个直觉性认知:DeepSeek启动这轮融资,核心原因并不是账上没钱。
据英国《金融时报》4月23日报道,知情者明确表示,DeepSeek“并不急需资金”。那为什么要融资?报道给出了一个关键答案:给员工手中的股票期权定出一个清晰的价值,从而留住核心研究人员,避免被竞争对手挖走。
过去几个月,DeepSeek已有多位核心研发人员确认离职,包括郭达雅、王炳宣、魏浩然等——这些名字流向了小米、腾讯、字节等大厂,带走的往往是更高的薪酬包和已经定价的期权。
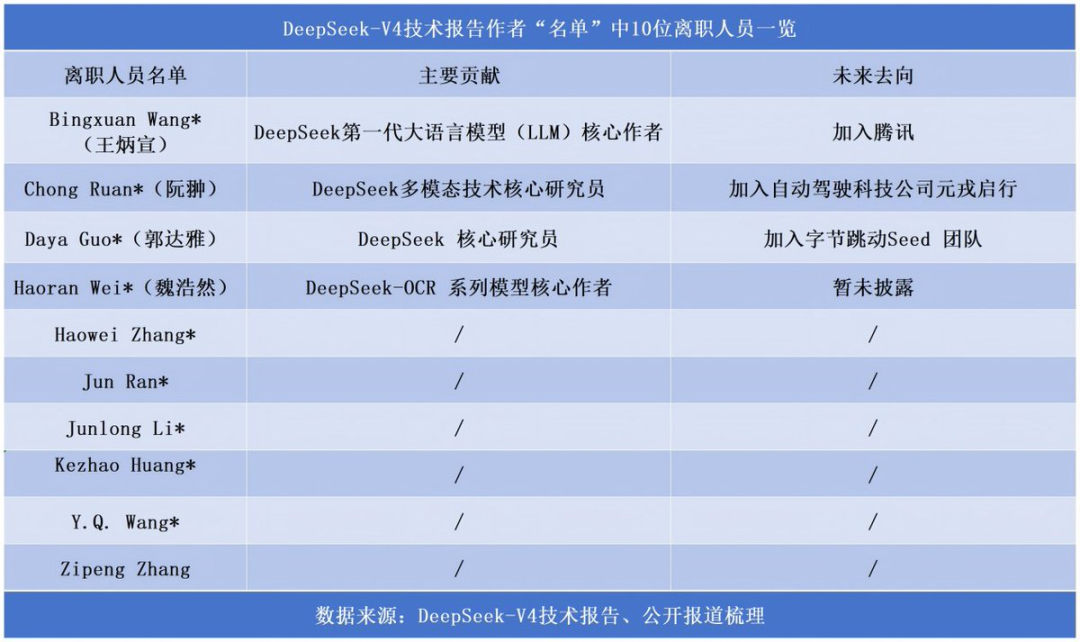
你可以跟资本说“我不需要钱”,但你很难跟一个顶尖研究员说“你的期权暂时不值钱,但请相信我”。在人才争夺战白热化的2026年,AI公司的核心竞争力已经不只是模型参数,更是那几十个能定义模型路线的人。融资在这里的角色,不是救命稻草,而是从“创始人驱动的实验室”转型为“股权激励驱动的现代公司”的成人礼。
其次,这笔钱是在为DeepSeek争取更长的竞争窗口。大模型赛道不是百米冲刺,而是持续迭代的耐力赛。训练更强模型需要算力,部署推理服务需要算力,企业客户要求稳定SLA和持续运维——这些都指向同一个方向:资金越充足,越有能力在多个方向同时布局。
据The Information报道,DeepSeek计划在6月推出V4.1,新版本将加入企业工具和多模态支持(同时处理图像和音频),并支持行业通用的MCP协议。更关键的是,公司已向部分投资者透露,计划把模型发布节奏加快到接近行业常规速度。融资,正在倒逼发布节奏。
02
估值跳涨的背后:
国家队进场与“卖方市场”的定价权
一个月之内,估值从100亿美元跳到超500亿美元。这不可能是业务基本面驱动的——V4再好,也不会让一家公司在一个月内身价翻五倍。
数字跳涨反映的是两件事:投资者的竞价热度,以及战略资本对DeepSeek的重新定价。
先看参与者的阵容。据多家媒体报道,与DeepSeek洽谈的投资方包括:国家集成电路产业投资基金(“国家大基金”)、多家互联网巨头、以及其他国资背景基金。投资门槛据说高达50亿人民币起投,甚至对LP也有身份要求——这不是在求人投钱,这是在筛选谁有资格上船。
其中最值得关注的,是国家大基金。这只基金自2014年成立以来,投的都是半导体硬科技——设备、材料、制造,从来没有投过一家大模型公司。如果最终领投落地,意味着DeepSeek被认定为“算力基础设施级”的战略资产,而不仅是“一家AI创业公司”。这个定性,比估值数字重要一百倍。
为什么是DeepSeek?答案可能藏在三个标签里:全链路国产芯片适配 + 开源路线 + 全球顶尖技术实力。
今年4月底发布的V4,全面适配华为昇腾芯片,从英伟达CUDA生态转向国产算力框架。这不是一次常规的模型迭代——它完成了中国AI从“模型是中国的,但算力底座是英伟达的”到“全栈自主”的战略脱钩。DeepSeek与华为打的这个配合,意义不亚于模型本身的突破。

再看阿里与DeepSeek“谈崩”的消息。据《白鲸实验室》5月8日报道,双方未能在融资具体条款上达成一致,原因是阿里的自有生态对DeepSeek适配度不高,而DeepSeek也不缺乏候选股东,希望尽量减少条款层面的束缚。这一细节透露出DeepSeek在谈判中的强势地位——它不是被动接钱,而是在主动筛选“谁有资格上船”。
03
融资之后:商业化从“选项”变“必选项”
估值需要被兑现
钱进来了,压力也随之而来。
DeepSeek过去最鲜明的标签之一,就是“不考虑商业化”。梁文锋曾公开表示,希望更多人、哪怕一个小app都可以低成本用上大模型,而不是让技术只掌握在少数公司手中形成垄断。这种技术理想主义赢得了开发者的尊重,但也让DeepSeek至今没有披露明确的规模化收入。
但融资改变了一切。 The Information的报道中有一句关键表述:“此次融资将促使DeepSeek加速落地营收规划、推进商业化盈利。”一旦引入外部资本——尤其是国家大基金这种战略投资者——“不商业化”就不再是选项。
DeepSeek的商业化可能有几条路径。最直接的是API收费,但这条路正面临激烈的价格竞争。V4-Pro的API定价,输出每百万Token只要6元人民币(促销期),而GPT-5.5是30美元(约216元),价差超过30倍。低价能抢市场,但Token生意的本质是规模效应,不是价格战。一旦补贴退坡,用户留存率才是真正的考验。
第二条路是企业私有化部署。据The Information报道,DeepSeek员工已经开始向各行业企业推广模型。工商银行及多家金融机构已率先部署DeepSeek模型,落地场景超过200个。这条路径收入更重、单客户金额更高,但交付复杂度也更高——企业客户关心的不只是模型效果,还包括数据安全、权限管理、合规审计和售后支持。DeepSeek如果进入这个市场,需要建立更强的ToB销售和交付体系。
第三条路是高端模型与高效模型的组合定价。V4-Pro负责复杂推理、代码和高价值任务,V4-Flash负责高频、低成本场景。这种双层产品体系,有利于在价格战中保留利润空间。V4.1被描述为将加入企业工具和多模态支持,明显指向企业客户和商业收入。

但最根本的挑战,是组织能力。DeepSeek过去的成功,更偏向研究和工程效率。而商业化需要销售、客户成功、行业解决方案、合作伙伴管理、财务规划和法务合规。融资之后,DeepSeek能否快速补齐这些能力,将决定估值能否被兑现。它需要避免两个极端:一个是过度商业化,导致研究能力被削弱;另一个是继续只重研究,不建立收入闭环。
DeepSeek的500亿融资传闻,不能简单理解为“钱更多,所以竞争力更强”。更准确的判断是:DeepSeek正在告别单纯的技术叙事,进入商业化、组织化和平台化的深水区。
它最宝贵的资产,不是某一轮融资,也不是某一个模型版本,而是过去展现出的技术效率和工程判断力。融资之后,真正的考验是:能否在资源变多、关注变多、压力变大的情况下,继续保持这种效率。
当Redis之父主动为DeepSeek V4打造推理引擎,当国家大基金的名字出现在潜在领投方名单里,当一家曾两次公开说“融资是谣言”的公司对500亿传闻保持沉默——这个沉默本身就是信息。
它意味着,中国AI的牌桌上,资源正在向少数玩家手中集中。而DeepSeek,已经从那个“不拿VC一分钱”的技术极客,变成了牌桌上最受关注的那个主导者。
融资如果落地,是新阶段的开始最好的证券公司,不是胜利的终点。
长宏网提示:文章来自网络,不代表本站观点。
相关文章



热点资讯
